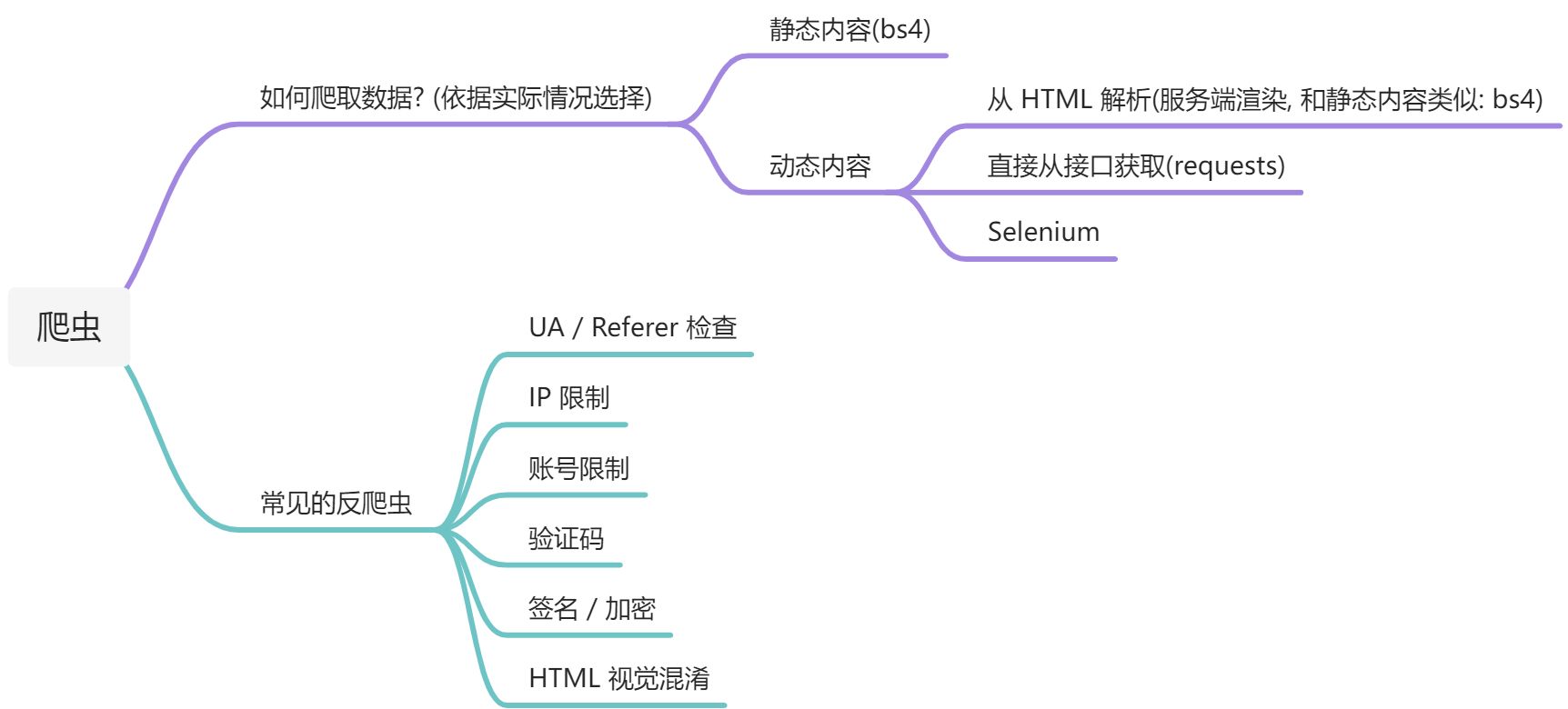
整理了爬虫的思路和常见的一些反爬应对手段.
爬虫所需的一些前置知识 基础 python 语法知识 (python 有十分方便完善的爬虫库) http 相关知识 (学会抓包, 并理解 http 请求与响应的含义) 基础的 html, css 知识 (理解 html 格式, 解析网页内容) 理解 json, xml 格式 (解析接口返回值) 快速学习: https://www.runoob.com/
可选的技能还有:
正则 (提取信息) Javascript (理解网页动态内容, 加密逆向) Android 知识 (APP 加密逆向) CV (验证码识别) SQL (存储大量爬取的内容) Linux (使用服务器长时间运行爬虫) etc. 获取并解析数据 构造请求并发送给服务器 通过抓包或分析 HTML 内容构造对应的请求并发送.https://www.telerik.com/fiddler/fiddler-classic https://docs.python-requests.org/en/latest/
1 2 3 def google_search (keyword ):return requests.get("https://www.google.com" , params={"q" : keyword})
解析响应内容 (具体操作方式与每个网站的设计方式有关) 对于内容直接嵌入在 HTML 中的: https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
1 2 3 4 5 6 7 8 9 10 11 12 "https://baike.baidu.com/search/word" ,"word" : keyword},"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36" ,"Referer" : "https://baike.baidu.com/" },10 )"html.parser" )"" for content in bs.find_all("div" , class_="para" ):if content.string is not None :"\n"
对于 API 返回内容的:
1 2 3 4 5 6 7 8 9 "https://music.163.com/api/search/get/web" ,"s" : name, "offset" : "0" , "limit" : "20" , "type" : "1" })print (r.json())print (r.json()['result' ]['songs' ][0 ]['id' ])
常见反爬虫与应对 User-Agent / Referer 检查 HTTP Headers 中包含的 UA 和 Referer 可以用来识别爬虫.
1 2 3 4 requests.get("https://www.example.com/" ,"User-Agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:47.0) Gecko/20100101 Firefox/47.0" ,"Referer" : "https://www.example.com/" }
IP 访问频率限制 使用同一个 IP 短时间内多次访问一个网站可能被判断为爬虫.
1 requests.get("https://www.example.com/" , proxies={"https" : "http://x.x.x.x:1080" })
可以购买网络上现有的代理池服务, 如 https://www.abuyun.com/ , https://http.zhimaruanjian.com/ .https://blog.lyc8503.site/post/sfc-proxy-pool/
账号访问频率限制 在访问需要登陆获取的信息时, 使用同一个账号的 Cookie 短时间内多次访问也会被判断为爬虫.
验证码 绕过方法:
较为简单的验证码可以直接处理一下后 OCR 识别.
滑块类验证码可以通过 CV 方法识别位置, 并滑动到指定位置.
1 2 3 4 5 6 abs (255 - target)return x, y
终极解决方案: 使用人工打码平台.
JS 加密 部分网站会对请求进行”签名” (请求中有 sign 或类似的参数), 或对结果进行加密.
使用 selenium 运行完整的浏览器, 操作简单但效率低下, 性能占用高, 适用于少量数据. 使用 PyexecJs 等方案在 Python 中直接运行加密相关的 js 代码. 优点是性能较好操作不太复杂, 缺点为配环境略麻烦, 对于大量混淆无法提取的 js 代码不适用. 人力分析 js 代码并使用 Python 重写加密相关代码. 优点是性能最好而且清晰明了, 缺点是需要学 Javascript 且人力分析代码比较费时和繁琐. 工具推荐: selenium / Chrome 自带的开发者工具
APP 加密 很多网站可能有其对应的安卓或 iOS APP, APP 上的反爬措施可能比网页端弱.https://apkpure.com/httpcanary-%E2%80%94-http-sniffer-capture-analysis/com.guoshi.httpcanary 反射大师 jadx appium , 但很麻烦, 不太推荐.
HTML 混淆 具体的情况较多较复杂, 但其实并没有非常常见, 例如:
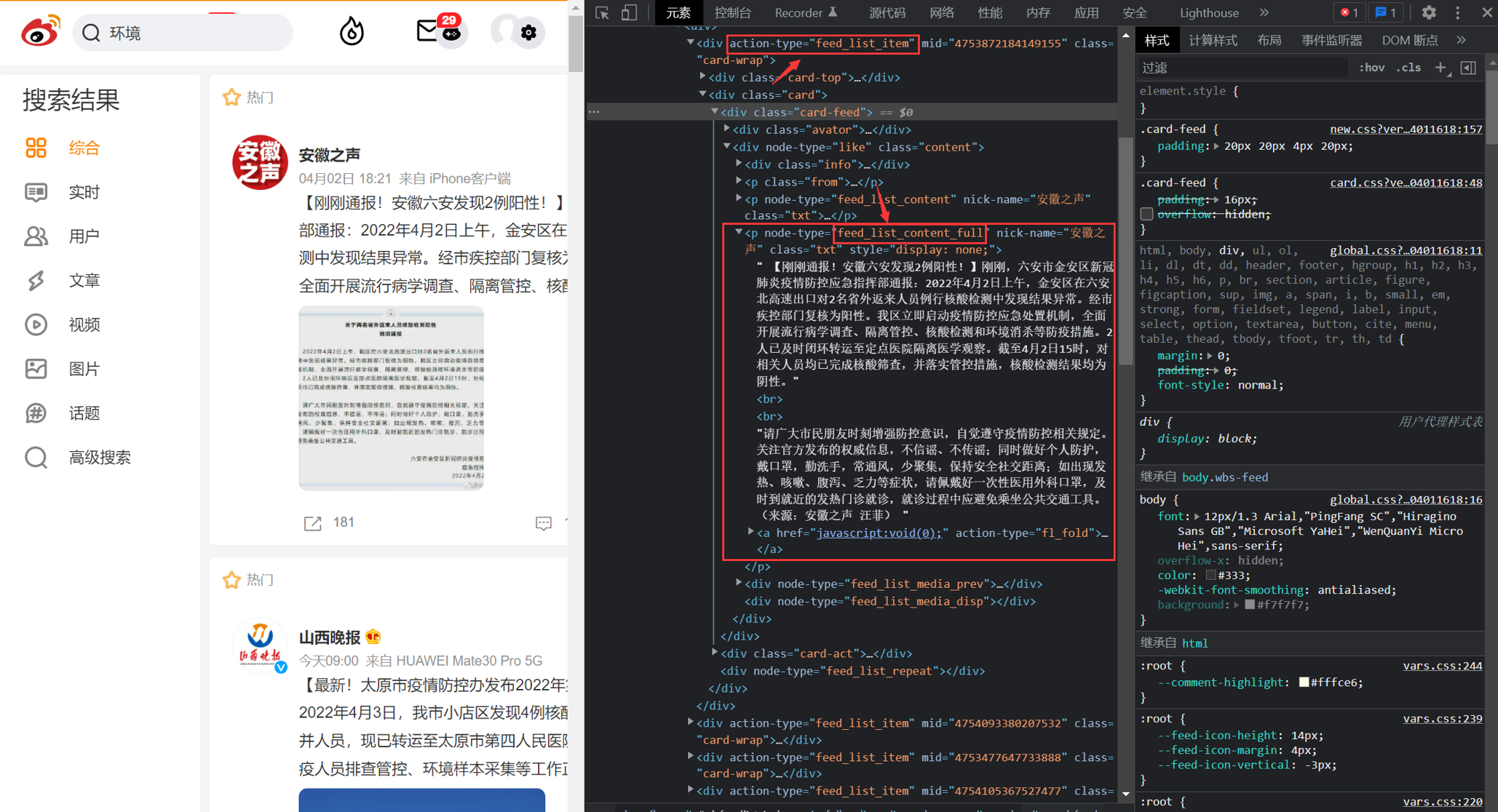
使用自定义字体, 实际上返回一堆乱码, 在浏览器中使用特定字体观察则正常. 使用 css 更改元素位置. 如真实数据 123 却返回 321, 再使用 css 将 1 和 3 位置调换. 将图片分为多片”拼图”返回, 再在页面上拼接显示. 实战尝试 微博爬虫 抓包查看请求, 发现微博的搜索请求很简单, 格式如下.https://s.weibo.com/weibo?q={keyword}&page={i}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 soup = BeautifulSoup(r.text, "html.parser" )"div" , attrs={"class" : "card-wrap" , "action-type" : "feed_list_item" })for j in feeds:if "mid" in j.attrs:try :"keyword: " + keyword + ", mid: " + j.attrs['mid' ])"p" , attrs={"node-type" : "feed_list_content_full" })if len (content) == 0 :"p" , attrs={"node-type" : "feed_list_content" })str (content[0 ])).strip().replace("\n\n" , "\n" )"p" , attrs={"node-type" : "feed_list_content" })[0 ].attrs['nick-name' ]"a" , attrs={"nick-name" : nick_name})[0 ].attrs['href' ]"a" , attrs={"suda-data" : re.compile (".*wb_time.*" )})[0 ].string.strip()"keyword" : keyword, "content" : content_text, "mid" : j.attrs['mid' ], "user" : nick_name,"uid" : uid, "time" : time_str, "timestamp" : int (time.time())}with open (save_path + j.attrs['mid' ] + ".json" , "w" ) as f:except Exception as e:"failed: " + j.attrs['mid' ] + ", " + str (e))else :"no mid found, discard" )
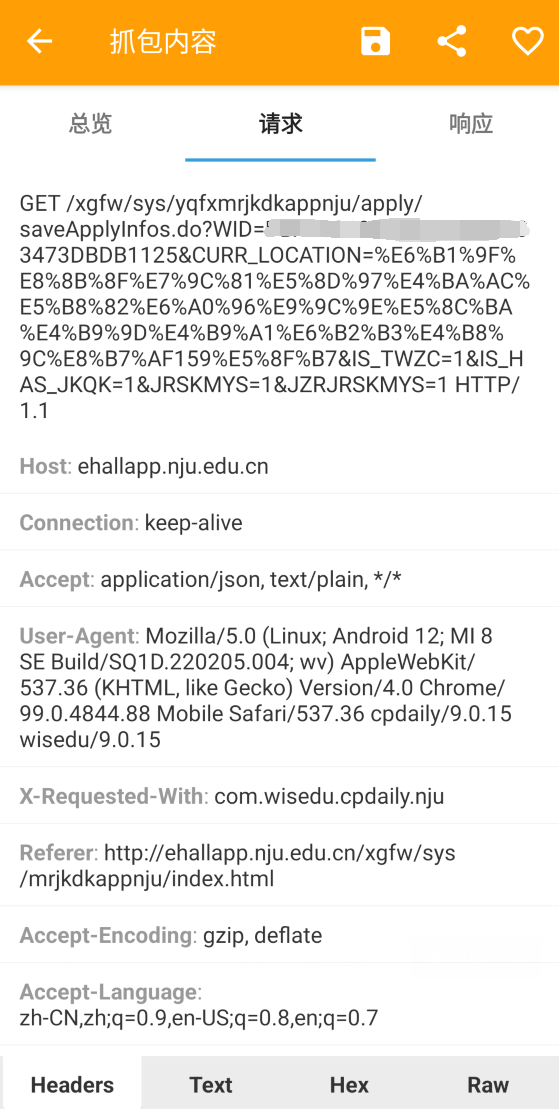
南大健康打卡自动化 使用 HttpCanary 抓包手机 APP 请求.
1 2 3 4 5 6 7 8 9 10 r = session.get('https://ehallapp.nju.edu.cn/xgfw/sys/yqfxmrjkdkappnju/apply/getApplyInfoList.do' )'data' ][0 ]if dk_info['TBZT' ] == "0" :"尝试打卡..." )'WID' ]"?WID={}&IS_TWZC=1&CURR_LOCATION={}&JRSKMYS=1&IS_HAS_JKQK=1&JZRJRSKMYS=1" .format ("https://ehallapp.nju.edu.cn/xgfw/sys/yqfxmrjkdkappnju/apply/saveApplyInfos.do" + data)"getApplyInfoList.do " + r.text)
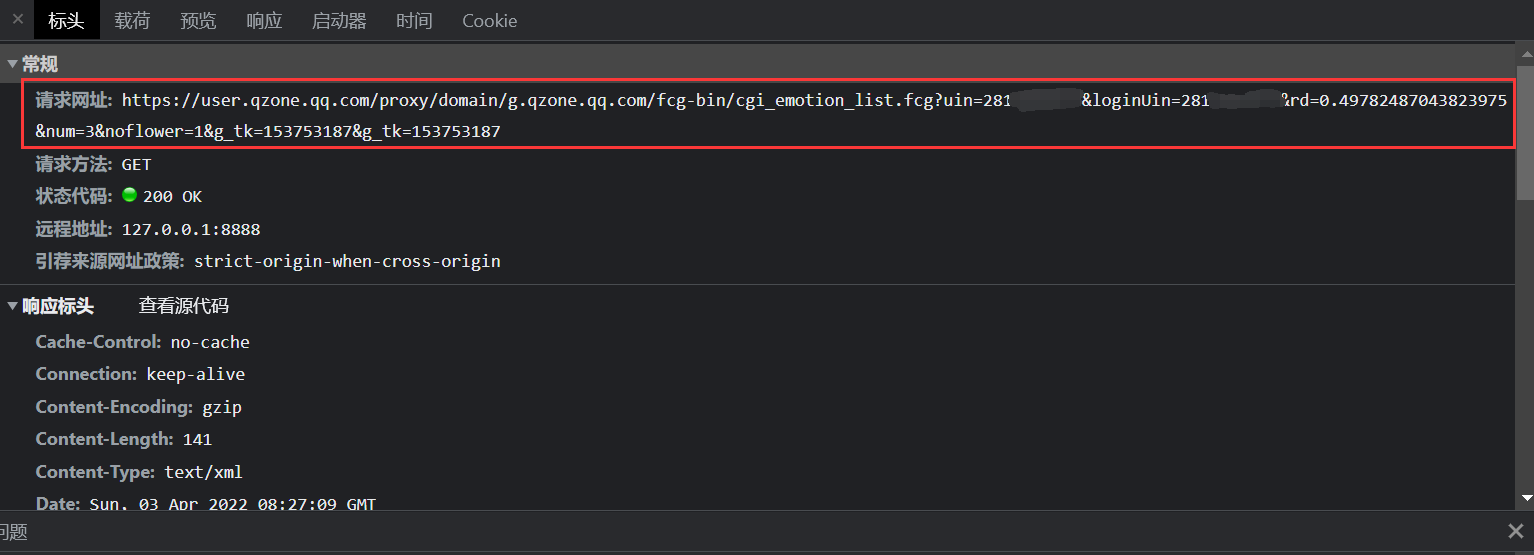
爬取 QQ 空间说说 使用 Chrome 开发工具抓包查看请求.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 QZONE .FrontPage .getACSRFToken = function (url ) {QZFL .util .URI (url);var skey;if (url) {if (url.host && url.host .indexOf ("qzone.qq.com" ) > 0 ) {QZFL .cookie .get ("p_skey" );else {var hash = 5381 ;for (var i = 0 , len = skey.length ;i < len;++i) {5 ) + skey.charAt (i).charCodeAt ();return hash & 2147483647 ;
直接可以将其改写为 Python 代码的形式.
1 2 3 4 5 6 def get_gtk (login_cookie):'p_skey' ]5381 for i in p_skey :5 ) + ord (i)return h & 2147483647
构造出请求发送给服务器, 发现服务器直接用 jsonp 格式返回了 json, 直接解析即可.
自动登录及 Cookie 的获取 QQ 空间网页版本的 Cookie 有效期较短, 若要持续爬取需要做自动登录.
登录有独立的 iframe, 写代码时记得 switch_to.frame(‘login_frame’) 腾讯滑动验证码
1 2 3 4 5 6 7 8 9 10 11 12 abs (255 - target)'tcaptcha_drag_thumb' )).perform()0.2 )0 ).perform()0.2 )'tcaptcha_drag_thumb' )).perform()
同样是抓包发现获取历年招生分数线的接口如下:
https://api.eol.cn/web/api/?local_batch_id=51&local_province_id=14&local_type_id=1&page=1&school_id=111&size=10&special_group=&uri=apidata/api/gk/score/special&year=2020&signsafe=69d89bdf5ca94281643ef5a6a32a2dd4
对于这个接口服务器检验了 signsafe 签名, 而且对返回的数据进行了加密.
{“code”:”0000”,”message”:”成功”,”data”:{“method”:”aes-256-cbc”,”text”:”eab8325abc5a1440b7708431e83f79ace……”},”location”:””,”encrydata”:””}
由于这里需要爬取的数据较多, selenium 并不是一个很好的选择, 直接逆向相关代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 return ("D23ABC@#56" ),"" ),endsWith (".json" ) ||endsWith (".txt" ) ||0 < Object .keys (u).length "?" +function (l ) {return Object .keys (l)sort ()map (function (e ) {var a = l[e];return ("keyword" !== e && "ranktype" !== e) ||decodeURI (decodeURI (l[e]))),"" concat (e, "=" )concat (void 0 === a ? "" : a)join ("&" );"" )),void 0 ),SIGN : h,str : m.replace (/^\/|https?:\/\/\// , "" )SIGN ),str ),a .HmacSHA1 (r.a .enc .Utf8 .parse (t), g)),a .enc .Base64 .stringify (g).toString ()),c ()(g)),signsafe = p),find (function (l ) {return l === u.uri ;"&signsafe=" + p)),abrupt ("return" ,i ()({url : e,method : a,timeout : n,data : (function (l, e ) {var a,if (Object .keys (e)sort ()forEach (function (l ) {return (u[l] = Array .isArray (e[l])toString ()"get" === l)return JSON .stringify (u);for (a in u)"elective" !== a && "vote" !== a) ||"" == u[a] ||1 == u[a].indexOf ("," )split (" " )split ("," ));return u;Object (b.a )(Object (b.a )({}, u),signsafe : p }then (function (l ) {return l.data ;catch (function (return {};then (function (l ) {var e, a, t, b, n;return (null != l &&null !== (a = l.data ) &&void 0 !== a &&text &&data =iv : u.uri ,text : l.data .text ,SIGN : hiv ),text ),SIGN ),a PBKDF2 (e, "secret" , {keySize : 8 ,iterations : 1e3 ,hasher : r.a .algo .SHA256 toString ()),a PBKDF2 (n, "secret" , {keySize : 4 ,iterations : 1e3 ,hasher : r.a .algo .SHA256 toString ()),a .lib .CipherParams .create ({ciphertext : r.a .enc .Hex .parse (a)a .AES .decrypt (a .enc .Hex .parse (e),iv : r.a .enc .Hex .parse (n) }JSON .parse (n.toString (r.a .enc .Utf8 )))),null !== (n = window .apiConfig ) &&void 0 !== n &&null !== (n = n.filterCacheList ) &&void 0 !== n &&length window .apiConfig .filterCacheList .forEach (function (l ) {new RegExp (l).test (t) || d.set (t, b);set (t, b)),
直接找到了发送对应请求相关的代码.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import base64import hmacfrom hashlib import sha1, md5"D23ABC@#56" .encode("utf-8" )def hash_hmac (code, key ):"utf-8" ), sha1).digest()return base64.b64encode(hmac_code).decode()def get_sign (url ):return md5(hash_hmac(url, KEY).encode("utf-8" )).hexdigest()
解密的部分在 js 代码的 L89 - L118, 发现用到了 PBKDF2 和 AES 算法.
1 2 3 4 5 6 7 8 9 10 import hmacfrom hashlib import pbkdf2_hmacfrom Crypto.Cipher import AES"D23ABC@#56" .encode("utf-8" )def decrypt_response (text, uri, password=pbkdf2_hmac("sha256" , KEY, b"secret" , 1000 , 32 ):lambda s: s[:-ord (s[len (s)-1 :])]"sha256" , uri.encode("utf-8" ), b"secret" , 1000 , 16 )return unpad(AES.new(password, AES.MODE_CBC, iv).decrypt(bytes .fromhex(text))).decode("utf-8" )
加解密部分都完成后就可以自己构造请求爬取数据了.
由于需要爬取的数据较多, 为了快速爬取, 还需要一个 IP 池.