全站分布式爬虫的首次尝试 - Lofter
自己以前写过不少爬虫, 但全部都是单机爬虫, 主要自动化爬取一些我关心的一小部分内容或者自动化某些流程.
但单机爬虫的速度总会遇到瓶颈, 获取的数据量有限, 于是想要尝试一下分布式爬虫, 同时也学习一些相关的技术.
选取目标
注意不要爬取涉及个人隐私的敏感数据或将爬取的数据商用, 也不要让爬虫程序对网站造成太大负担, 影响网站正常运行.
先找一个相对简单的软件下手, 从 Lofter 爬一些同人文下来.(x
主要是从我常用的几个软件中测试发现, Lofter 相关 API 不需要登录, 且对 IP 没有频次限制, 不需要 IP 池或者账号池, 主要受限在带宽和网络连接数, 能发挥集群的作用. 而且作为网易旗下的平台相对能接纳比较大的流量, 爬虫流量不至于对其造成显著影响.
搭建集群
寻找 VPS
集群, 顾名思义就是得有一堆机器. 首先得找到一堆机器用来跑集群.
如果使用一些主要面向个人/开发者的云服务提供商(如 DigitalOcean, Vultr)其实价格不会特别高.
但我还是穷(想要白嫖), 于是我用信用卡向 GCP 申请(白嫖)了 90 天 300 美刀的试用额度. 开几台爬虫用的机器应该是完全足够的.
通过 Ping 工具 发现 Lofter 的海外域名解析到了新加坡的 AWS, 于是将主机选在了新加坡.
容器编排
Kuboard 可以安装自动部署 K8s 集群, AutoK3s 也可以直接搭建 GCE 集群. 但对于爬虫来说, 这些编排工具还是太重量级了.
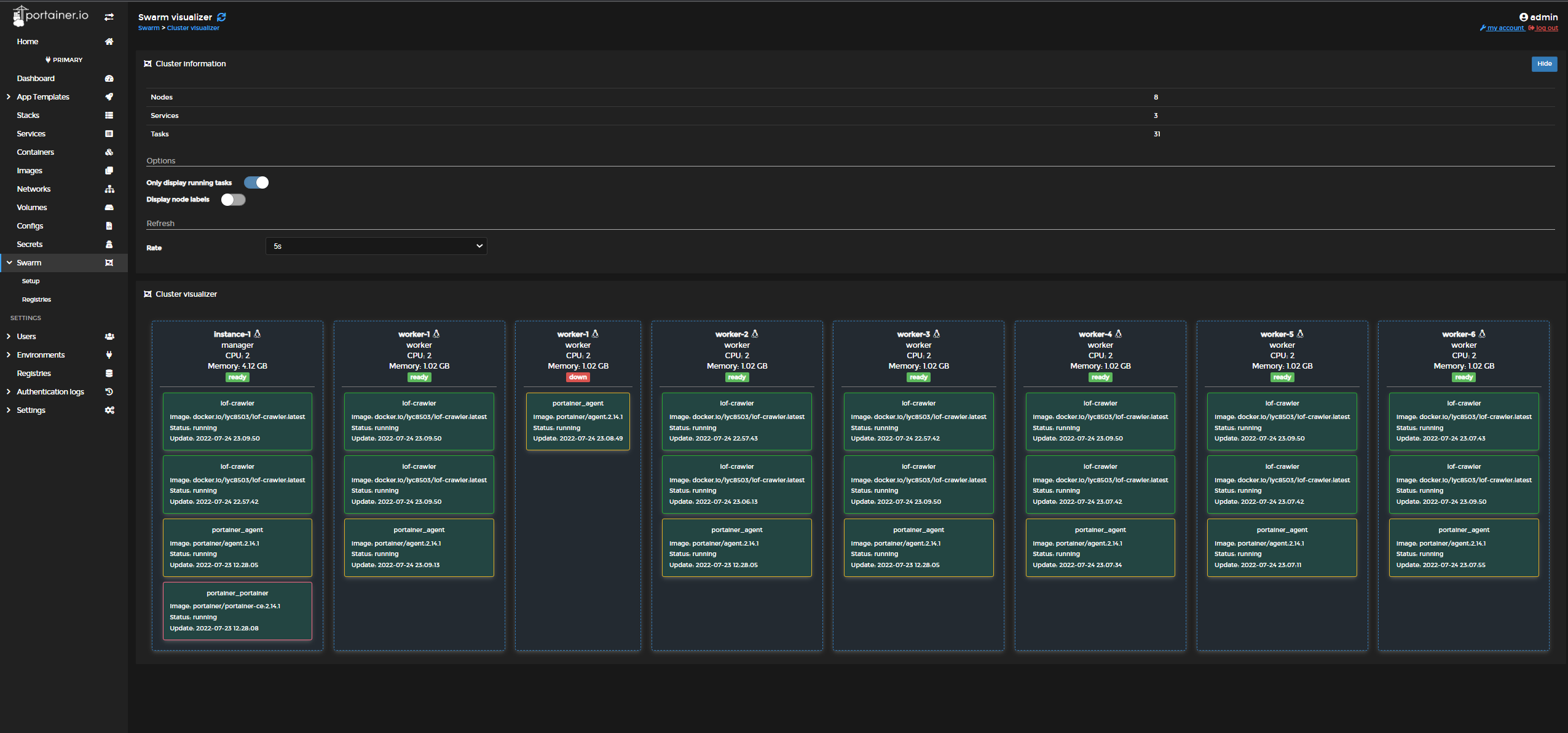
所以选择了比较简单易用且轻量的 Docker Swarm 集群.
开台主机充当集群的 Manager 同时用于运行 Redis + MongoDB. Redis 用于爬虫间同步队列, MongoDB 用于储存爬虫获取的数据.
配置十分简单
主机
sudo docker swarm init之后参考 https://docs.portainer.io/start/install/server/swarm/linux 配置 Portainer 面板.节点
使用主机给出的加入集群命令直接加入, 配置好一台机器后保存为模板, 批量创建剩下的机器.
爬虫编写
观察 Lofter 网站, 寻找突破口.
Lofter 本身内容的获取部分并不困难, 我的思路如下:
随机选定一个 TAG, 加入队列.
从队列中取出一个 TAG, 爬取其热门内容, 同时将内容中包含的未爬取的 TAG 加入队列.
重复第二步, 直至队列为空.
爬取 TAG 相关内容的代码我参考了 https://github.com/IshtarTang/lofterSpider 的部分.
爬取所有 TAG 后再获取所有作者信息, 爬取所有作者发布的文章.
爬取作者文章由于各作者主页布局都不相同, 我抓包分析了 Android API 进行爬取.
爬虫运行
由于 Lofter 获取 TAG 和作者的 API 都能一次性返回 100 条结果(包含完整的文章内容), 爬虫整体运行还算高效.
而且相关接口都没有对 IP 进行频次限制, 也不需要登录账号.
最后爬 TAG + 作者这两轮花了大概一个多礼拜.
最后爬取 TAG 获取了 4431w 条内容, 再顺藤摸瓜爬作者获得了整整 1.2 亿条数据…
数据分析
鸽子中, 下次有空再补~

